前言 我们在spring(2) web应用中spring IOC容器初始化(2) 中有讲到除了默认命名空间之外,还有一个自定义命名空间的解析。那么我们这次所要阅读的注解方式的解析就是自定义命名空间解析的一种。
我们可以经常在配置文件中看到如下面的几行配置,
1 2 3 <context:component-scan base-package ="study.cayun.login" > <context:exclude-filter type ="annotation" expression ="org.springframework.stereotype.Controller" /> </context:component-scan >
我们这次就以这个配置来阅读自定义命名空间中注解方式。
parseCustomElement方法 1 2 3 4 5 6 7 8 9 public BeanDefinition parseCustomElement (Element ele, BeanDefinition containingBd) { String namespaceUri = getNamespaceURI(ele); NamespaceHandler handler = this .readerContext.getNamespaceHandlerResolver().resolve(namespaceUri); if (handler == null ) { error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]" , ele); return null ; } return handler.parse(ele, new ParserContext (this .readerContext, this , containingBd)); }
这个方法是解析自定义命名空间的入口。
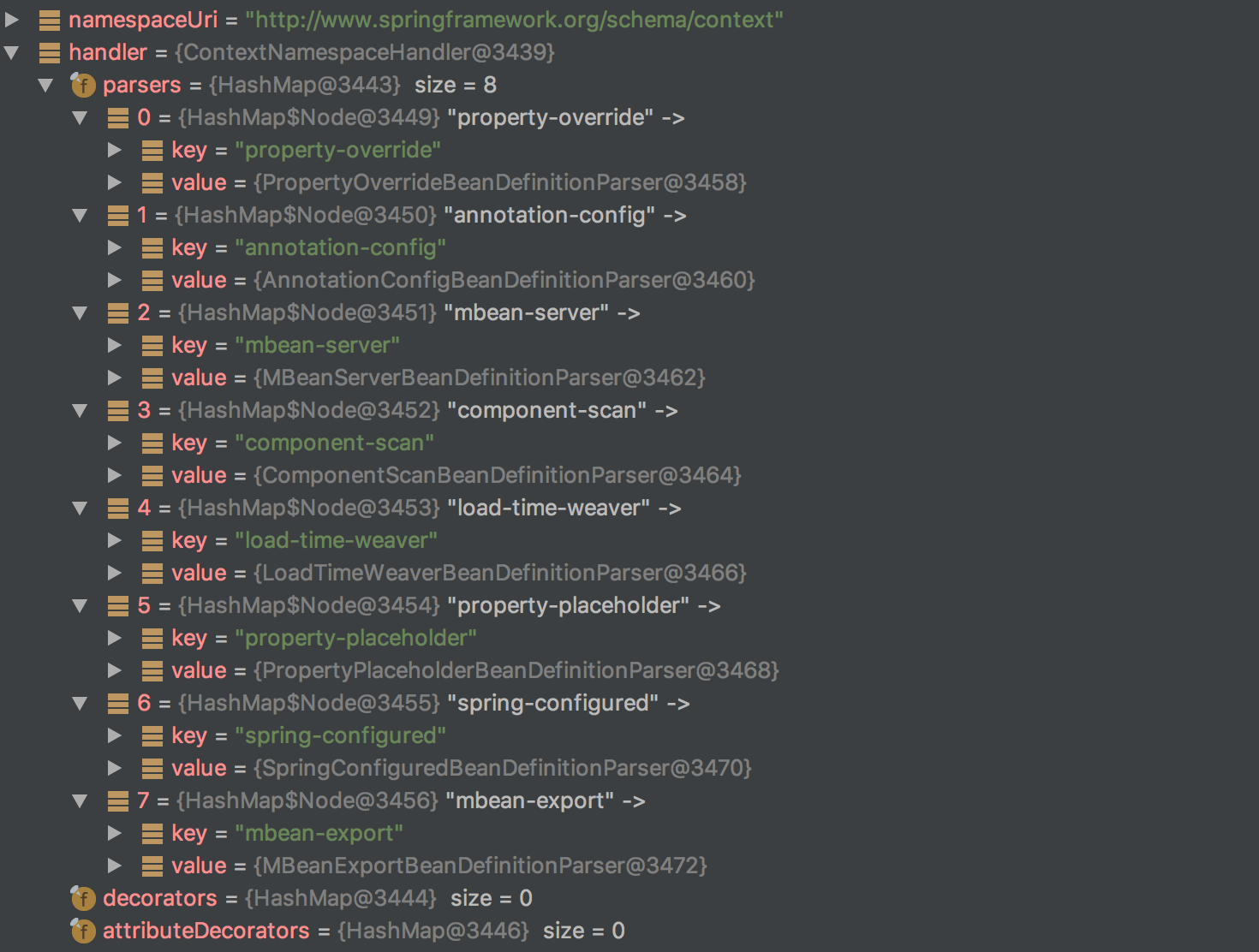
打开调试,我们可以发现handler的结果为这样,
从调试结果中我们可以看到 http://www.springframework.org/schema/context 这个命名空间中包含八种解析器:
元素名
解析器
property-override
PropertyOverrideBeanDefinitionParser
annotation-config
AnnotationConfigBeanDefinitionParser
mbean-server
MBeanServerBeanDefinitionParser
component-scan
ComponentScanBeanDefinitionParser
load-time-weaver
LoaderTimeWeaverBeanDefinitionParser
property-placeholder
PropertyPlaceHolderBeanDefinitionParser
spring-configured
SpringConfiguredBeanDefinitionParser
mbean-export
MBeanExportBeanDefinitionParser
而我们这次的component-scan很显然就是使用的ComponentScanBeanDefinitionParser。
解析过程 进入handler.parse方法,如下,
1 2 3 4 5 6 7 8 9 10 11 public BeanDefinition parse (Element element, ParserContext parserContext) { String[] basePackages = StringUtils.tokenizeToStringArray(element.getAttribute(BASE_PACKAGE_ATTRIBUTE), ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS); ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element); Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages); registerComponents(parserContext.getReaderContext(), beanDefinitions, element); return null ; }
第一步首先是获取base-package属性,我们继续看接下来又做了些什么
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 protected ClassPathBeanDefinitionScanner configureScanner (ParserContext parserContext, Element element) { XmlReaderContext readerContext = parserContext.getReaderContext(); boolean useDefaultFilters = true ; if (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)) { useDefaultFilters = Boolean.valueOf(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)); } ClassPathBeanDefinitionScanner scanner = createScanner(readerContext, useDefaultFilters); scanner.setResourceLoader(readerContext.getResourceLoader()); scanner.setEnvironment(parserContext.getDelegate().getEnvironment()); scanner.setBeanDefinitionDefaults(parserContext.getDelegate().getBeanDefinitionDefaults()); scanner.setAutowireCandidatePatterns(parserContext.getDelegate().getAutowireCandidatePatterns()); if (element.hasAttribute(RESOURCE_PATTERN_ATTRIBUTE)) { scanner.setResourcePattern(element.getAttribute(RESOURCE_PATTERN_ATTRIBUTE)); } try { parseBeanNameGenerator(element, scanner); } catch (Exception ex) { readerContext.error(ex.getMessage(), readerContext.extractSource(element), ex.getCause()); } try { parseScope(element, scanner); } catch (Exception ex) { readerContext.error(ex.getMessage(), readerContext.extractSource(element), ex.getCause()); } parseTypeFilters(element, scanner, readerContext, parserContext); return scanner; }
在这个部分我们可以看到一个很重要的东西,就是默认USE_DEFAULT_FILTERS_ATTRIBUTE为true,事实上,在默认的element属性中就默认有这么两条
1 2 annotation-config=true use-default-filters=true
为什么说这块地方很重要呢?我们可以进入createScanner方法看一看就知道了,createScanner方法最终调用了这个方法registerDefaultFilters,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 protected void registerDefaultFilters () { this .includeFilters.add(new AnnotationTypeFilter (Component.class)); ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader(); try { this .includeFilters.add(new AnnotationTypeFilter ( ((Class<? extends Annotation >) ClassUtils.forName("javax.annotation.ManagedBean" , cl)), false )); logger.debug("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning" ); } catch (ClassNotFoundException ex) { } try { this .includeFilters.add(new AnnotationTypeFilter ( ((Class<? extends Annotation >) ClassUtils.forName("javax.inject.Named" , cl)), false )); logger.debug("JSR-330 'javax.inject.Named' annotation found and supported for component scanning" ); } catch (ClassNotFoundException ex) { } }
在这段代码中我们可以看到,默认的include过滤器中就已经存在Component了,这也就是为什么我们在配置中并不需要配置context:include-filter type=”annotation” expression=”org.springframework.stereotype.Service”之类的了,因为Service其实本身也是继承的Component。
至于解析BeanNameGenerator和Scope的部分我们此处就不细讲了,我们直接来看看过滤器的解析,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 protected void parseTypeFilters ( Element element, ClassPathBeanDefinitionScanner scanner, XmlReaderContext readerContext, ParserContext parserContext) { ClassLoader classLoader = scanner.getResourceLoader().getClassLoader(); NodeList nodeList = element.getChildNodes(); for (int i = 0 ; i < nodeList.getLength(); i++) { Node node = nodeList.item(i); if (node.getNodeType() == Node.ELEMENT_NODE) { String localName = parserContext.getDelegate().getLocalName(node); try { if (INCLUDE_FILTER_ELEMENT.equals(localName)) { TypeFilter typeFilter = createTypeFilter((Element) node, classLoader); scanner.addIncludeFilter(typeFilter); } else if (EXCLUDE_FILTER_ELEMENT.equals(localName)) { TypeFilter typeFilter = createTypeFilter((Element) node, classLoader); scanner.addExcludeFilter(typeFilter); } } catch (Exception ex) { readerContext.error(ex.getMessage(), readerContext.extractSource(element), ex.getCause()); } } } }
其实这部分只是简单地解析了一下include-filter和exclude-filter属性,并将其添加进scanner中。
doScan方法 这个方法是ClassPathBeanDefinitionScanner类中的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 protected Set<BeanDefinitionHolder> doScan (String... basePackages) { Assert.notEmpty(basePackages, "At least one base package must be specified" ); Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet <BeanDefinitionHolder>(); for (String basePackage : basePackages) { Set<BeanDefinition> candidates = findCandidateComponents(basePackage); for (BeanDefinition candidate : candidates) { ScopeMetadata scopeMetadata = this .scopeMetadataResolver.resolveScopeMetadata(candidate); candidate.setScope(scopeMetadata.getScopeName()); String beanName = this .beanNameGenerator.generateBeanName(candidate, this .registry); if (candidate instanceof AbstractBeanDefinition) { postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName); } if (candidate instanceof AnnotatedBeanDefinition) { AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate); } if (checkCandidate(beanName, candidate)) { BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder (candidate, beanName); definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this .registry); beanDefinitions.add(definitionHolder); registerBeanDefinition(definitionHolder, this .registry); } } } return beanDefinitions; }
我们直接来看这个函数调用的几个比较关键的方法.
findCandidateComponents方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public Set<BeanDefinition> findCandidateComponents (String basePackage) { Set<BeanDefinition> candidates = new LinkedHashSet <BeanDefinition>(); try { String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + resolveBasePackage(basePackage) + "/" + this .resourcePattern; Resource[] resources = this .resourcePatternResolver.getResources(packageSearchPath); boolean traceEnabled = logger.isTraceEnabled(); boolean debugEnabled = logger.isDebugEnabled(); for (Resource resource : resources) { if (traceEnabled) { logger.trace("Scanning " + resource); } if (resource.isReadable()) { try { MetadataReader metadataReader = this .metadataReaderFactory.getMetadataReader(resource); if (isCandidateComponent(metadataReader)) { ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition (metadataReader); sbd.setResource(resource); sbd.setSource(resource); if (isCandidateComponent(sbd)) { if (debugEnabled) { logger.debug("Identified candidate component class: " + resource); } candidates.add(sbd); } else { if (debugEnabled) { logger.debug("Ignored because not a concrete top-level class: " + resource); } } } else { if (traceEnabled) { logger.trace("Ignored because not matching any filter: " + resource); } } } catch (Throwable ex) { throw new BeanDefinitionStoreException ( "Failed to read candidate component class: " + resource, ex); } } else { if (traceEnabled) { logger.trace("Ignored because not readable: " + resource); } } } } catch (IOException ex) { throw new BeanDefinitionStoreException ("I/O failure during classpath scanning" , ex); } return candidates; }
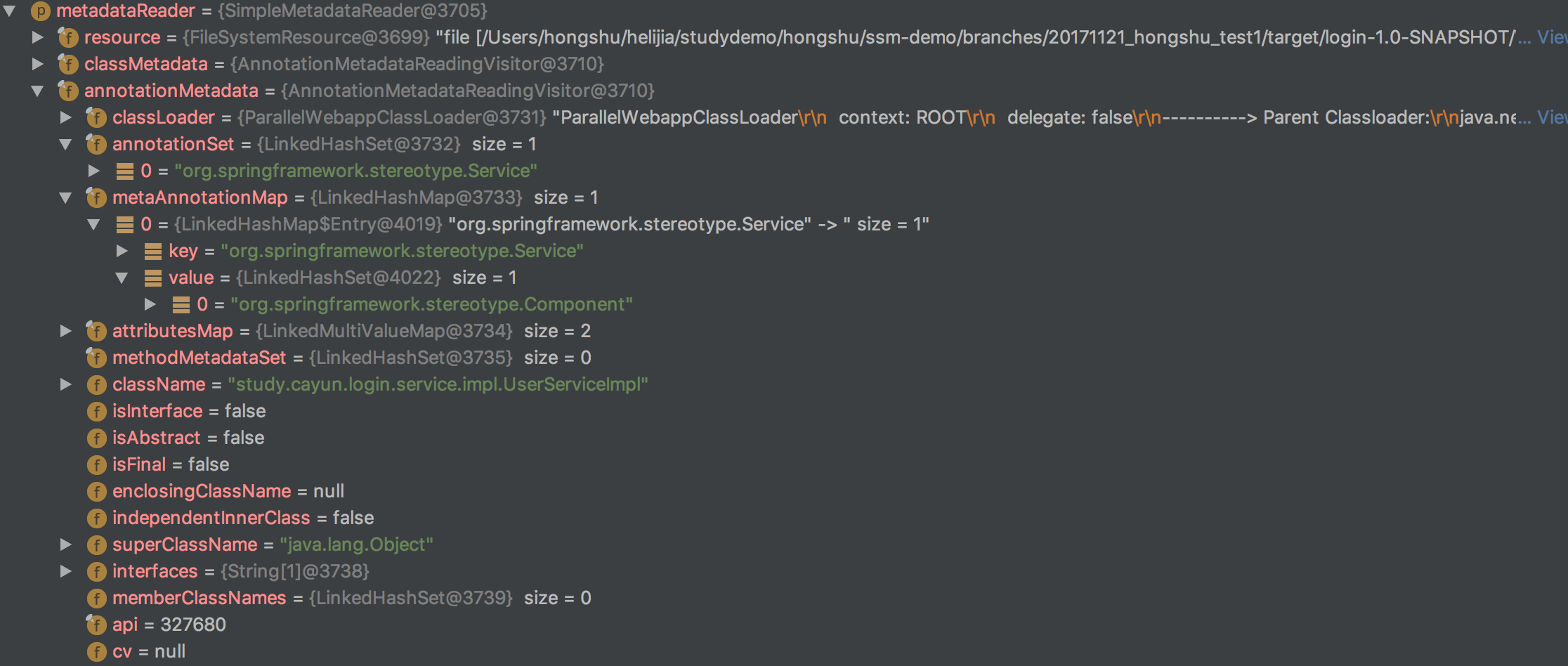
前面一部分主要是匹配路径下的所有资源。我们主要关注的是isCandidateComponent这个方法。在这之前,我们先来看一下metedataReader中都有些什么内容,下面是我们当前读取的资源,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Service public class UserServiceImpl implements UserService { @Autowired private UserMapper userMapper; public boolean isExist (UserVo userVo) { List<UserModel> users = userMapper.queryUsers(userVo.getUsername()); if (users.isEmpty()) { return false ; } UserModel user = users.get(0 ); if (!StringUtils.isNullOrEmpty(userVo.getPassword()) && userVo.getPassword().equals(user.getPassword())) { return true ; } return false ; } public boolean insertUser (UserVo userVo) { UserModel userModel = new UserModel (); userModel.setUsername(userVo.getUsername()); userModel.setPassword(userVo.getPassword()); System.out.println(userModel); try { System.out.println(userMapper.insertUser(userModel)); } catch (Exception e) { e.printStackTrace(); return false ; } return true ; } }
这个里面我们看到有一个@Service注解。那么我们看一下其相应的metedataReader,
我们需要关注的是annotationSet和metaAnnotationMap中的内容,因为等会儿我们就会用到这两块内容。
isCandidateComponent方法 我们进入到isCandidateComponent这个方法中,
1 2 3 4 5 6 7 8 9 10 11 12 13 protected boolean isCandidateComponent (MetadataReader metadataReader) throws IOException { for (TypeFilter tf : this .excludeFilters) { if (tf.match(metadataReader, this .metadataReaderFactory)) { return false ; } } for (TypeFilter tf : this .includeFilters) { if (tf.match(metadataReader, this .metadataReaderFactory)) { return isConditionMatch(metadataReader); } } return false ; }
根据这段代码,我们可以从整体知道整个的匹配过程。
首先匹配exclude列表,若是匹配成功直接返回false
接着再判断是否存在于include列表且满足匹配条件
那么概括一下就是这样的,一个注解若是需要被匹配,必须满足这样一个要求:存在于include-filter且不存在于exclude-filter(不考虑@Conditional注解的情况下)
match方法 接下来我们继续分析匹配的具体细节,进入match方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public boolean match (MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException { if (matchSelf(metadataReader)) { return true ; } ClassMetadata metadata = metadataReader.getClassMetadata(); if (matchClassName(metadata.getClassName())) { return true ; } if (this .considerInherited) { if (metadata.hasSuperClass()) { Boolean superClassMatch = matchSuperClass(metadata.getSuperClassName()); if (superClassMatch != null ) { if (superClassMatch.booleanValue()) { return true ; } } else { if (match(metadata.getSuperClassName(), metadataReaderFactory)) { return true ; } } } } if (this .considerInterfaces) { for (String ifc : metadata.getInterfaceNames()) { Boolean interfaceMatch = matchInterface(ifc); if (interfaceMatch != null ) { if (interfaceMatch.booleanValue()) { return true ; } } else { if (match(ifc, metadataReaderFactory)) { return true ; } } } } return false ; }
默认情况下this.considerInherited和this.considerInterfaces均为false。
那我们就来看一看matchSelf和matchClassName。
matchSelf的代码如下,
1 2 3 4 5 protected boolean matchSelf (MetadataReader metadataReader) { AnnotationMetadata metadata = metadataReader.getAnnotationMetadata(); return metadata.hasAnnotation(this .annotationType.getName()) || (this .considerMetaAnnotations && metadata.hasMetaAnnotation(this .annotationType.getName())); }
1 2 3 public boolean hasAnnotation (String annotationType) { return this .annotationSet.contains(annotationType); }
1 2 3 4 5 6 7 8 9 public boolean hasMetaAnnotation (String metaAnnotationType) { Collection<Set<String>> allMetaTypes = this .metaAnnotationMap.values(); for (Set<String> metaTypes : allMetaTypes) { if (metaTypes.contains(metaAnnotationType)) { return true ; } } return false ; }
可以看到这部分的逻辑就是首先判断注解集合中有没有相应注解(前面有提到过,include列表中默认就有Component注解,而当前TypeFilter中就是Component注解),在我们的注解集合中只有Service注解,并没有Component注解。但是对于第二个判断条件,判断元注解中是否有相应注解,从上面的调试结果来看,可以知道元注解中Service对应的正是Component注解。
registerComponents方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 protected void registerComponents ( XmlReaderContext readerContext, Set<BeanDefinitionHolder> beanDefinitions, Element element) { Object source = readerContext.extractSource(element); CompositeComponentDefinition compositeDef = new CompositeComponentDefinition (element.getTagName(), source); for (BeanDefinitionHolder beanDefHolder : beanDefinitions) { compositeDef.addNestedComponent(new BeanComponentDefinition (beanDefHolder)); } boolean annotationConfig = true ; if (element.hasAttribute(ANNOTATION_CONFIG_ATTRIBUTE)) { annotationConfig = Boolean.valueOf(element.getAttribute(ANNOTATION_CONFIG_ATTRIBUTE)); } if (annotationConfig) { Set<BeanDefinitionHolder> processorDefinitions = AnnotationConfigUtils.registerAnnotationConfigProcessors(readerContext.getRegistry(), source); for (BeanDefinitionHolder processorDefinition : processorDefinitions) { compositeDef.addNestedComponent(new BeanComponentDefinition (processorDefinition)); } } readerContext.fireComponentRegistered(compositeDef); }
该方法是用来注册组件的。我们可以看到里面有一个annotation-config的注册流程,这个其实对应的就是自定义命名空间中的annotation-config标签。因为默认值为true,所以component-scan默认就已经包含了annotation-config的功能。
这部分主要是用来注册
ConfigurationAnnotationProcessor
AutowiredAnnotationProcessor
RequiredAnnotationProcessor
CommonAnnotationProcessor
PersistenceAnnotationProcessor
这几个PostProcessor的。
此处更详细的解释可以自行搜索annotation-config。
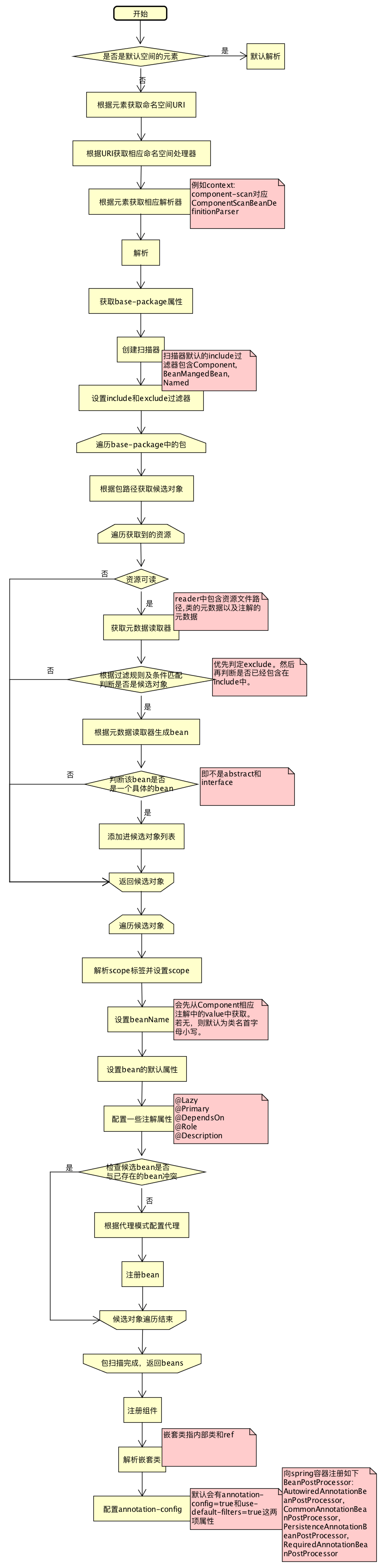
流程图